AWS architecture outline
If you talk about the omni-present buzzword cloud computing, you will inevitably stumble over Amazon Web Services . Sounds super cool and everybody gets excited about it, but I for my part was simply overwhelmed by the amount of services and products available from the platform.
The good news for us bioinformaticians is - and probably all cloud computing professionals handling on enterprise solutions are going to beat me for this statement - for setting up a proper and failsafe analysis pipeline with AWS, you only need a tiny fraction of those and can ignore the rest. In this post, I will walk you through the essential AWS building blocks I deem required for a basic bioinformatics processing pipeline, their characteristics, caveats and how they play together.
AWS building blocks
If you are familiar with cluster computing environments, you should not have a hard time to find the same architecture principal when building your own custom cluster computing environment in the cloud with AWS. I will elaborate on those pieces I encountered when building up a basic processing pipeline:
S3for storage of input and auxiliary (e.g. index) filesEBSas local compute storageAMIMachine image (the operating system) to be run on your instancesEC2instances that do the actual computationECSto create your “software” from Docker containers to run on your instancesAWS Batchthat handles everything from submission to scaling and proper finalization of your individual jobs
In the limited number of pipelines I have set up to run in AWS (they can also run on any other compute environment, but that’s a different later story) I have never used any services beyond that. For anything that involves reading e.g. raw read files, processing them and retreiving the output one should be able to make do with a combination of those. This can probably be optimized or done more elegantly with different services, but I had some discussions on this with various people and we have not come across a solution that could do it at a lower cost.
S3 - Simple Storage Service
This is the long-term storage solution from AWS. If you are familiar with a compute environment, this would be your globally accessible file-system were you store all your important files, reference genomes, alignment-indices - you name it. Contrary to the storage you are used to (unless you copy files locally to your node temporary storage for fast I/O), none of the files on S3 are directly read or written when utilizing EC2 instances for computational tasks. Before any pipeline start, all of the necessary files have to present in S3 such as:
- Input files:
- Raw read files (
fastq,bam,…) - Quantification tables (
txt,tsv,csv,…)
- Raw read files (
- Reference files:
- Genome sequence (
fasta) - Feature annotations (
gtf,bed, …)
- Genome sequence (
- Index files:
- Alignment indices (
bwa,bowtie,STAR,…) - Exon junction annotations (
gtf, …) - Transcriptome indices (
callisto,salmon, …)
- Alignment indices (
S3 also will be the final storage location where any of your final output files produced by your pipeline will end up. Since only S3 is long-term storage, usually you don’t have to worry about deleted intermediate or temporary files produced by your pipeline since they will be discarded after your instance has finished processing a given task.
Upload to S3 does not come with any cost, however downloading data from S3 is charged at around 10 cent / GB. Storage on S3 is charged at a per GB / per month basis. So I guess the fact that they charge data downloads is just merely based on the fact that you could up/download data in-between for free and thus circumvent the storage cost which they want to prevent.
EBS - Elastic Block Store
Every launched instance comes with a root volume of a limited size (8 GB) where all the OS and Service files are located required to start up an instance. To each instance, you can (and often must) attach additional volumes - EBS volumes - of configurable size where your data goes.
There are 3 things to consider when choosing your EBS size
- It needs to be large enough to store all input files for a given job
- This includes all auxiliary files such as index files!
- It needs to be large enough to store all intermediate files for a given job
- It needs to be large enough to store all output files from a given job
Remember - S3 data is never directly accessed from your instance, but always copied to your local EBS volume!
Estimating EBS volume sizes gave me a hard time initially and I did a lot of benchmarking runs - if it is too small, your jobs will crash. In practice, I found that EBS cost is a negligible fraction of your overall cost - so in the end, I ended up being very generous on EBS volume sizes.
AMI - Amazon Machine Image
The AMI is basically Amazon’s version of an image similar to Virtual Machine images. They offer quite a variety of OS base versions in their store (Linux, Windows etc.), but what you would usually want to go for is extending any of those base images yourself with all the software you need during your pipeline run. These days with Docker , usually there is very little effort to setup your software environment, but even then you will in most cases have to install at least the AWS Command Line Interface to copy files from and to S3.
EC2 - Elastic Compute Cloud
EC2 is the part where you bring the computing heat: These are the instances upon which you launch your AMIs, attach your EBS volumes and then do some heavy computation. EC2 instances come in all form and shapes - depending on your demands. Below is an excerpt of compute optimized instance types, but depending on the application you might go for memory optimized, storage optimized GPUs, you name it.
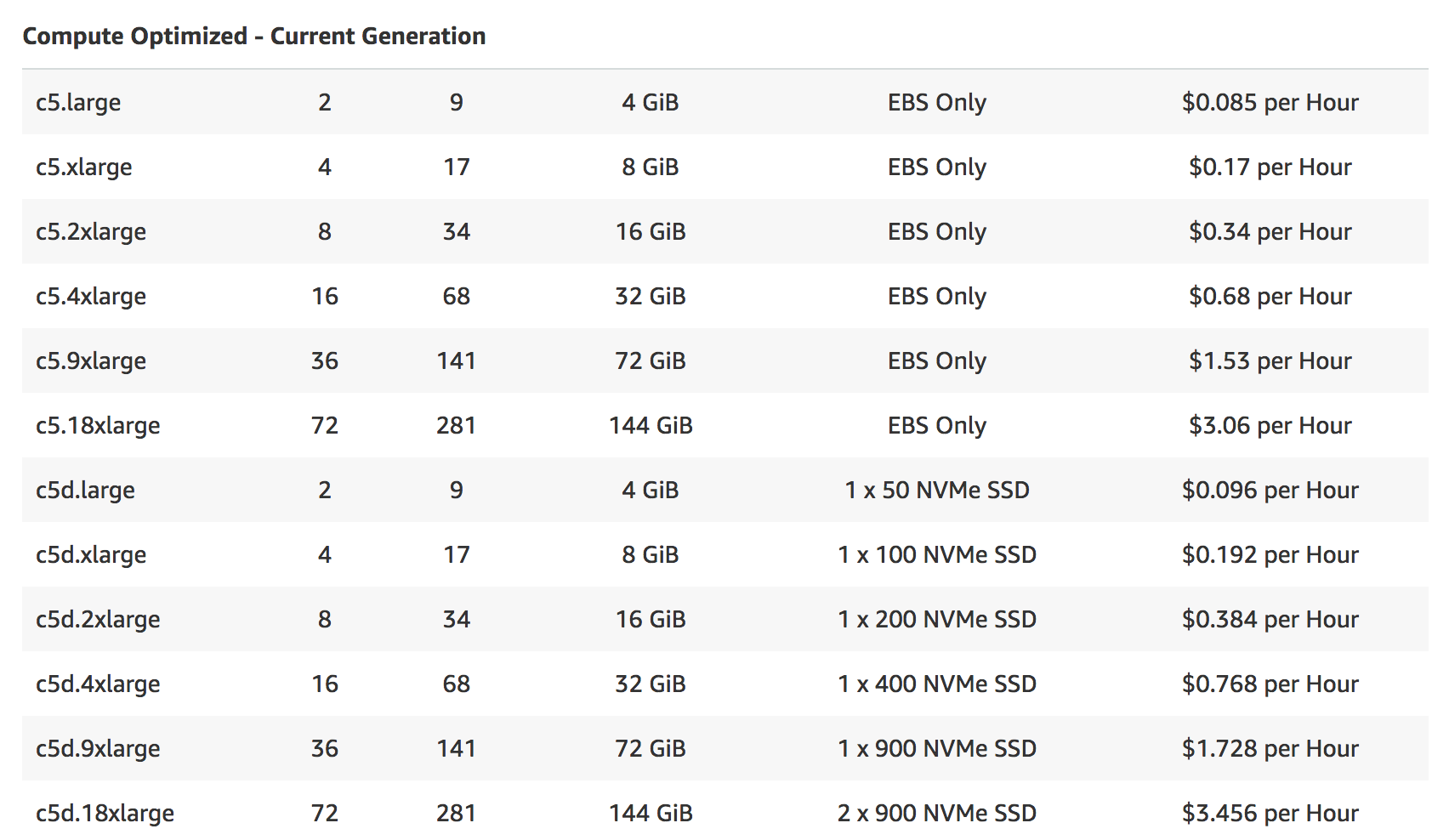
The cool thing about them - probably you noticed already if you did the Math - is in terms of cost, it does not matter whether you pick a smaller or a larger instance. The price will scale exactly linearly, meaning you don’t need to squeeze in two jobs in a 2-timers bigger instance necessarily - which will be important at a later point.
ECS - Elastic Container Service
This definition and especially it’s distinction from AWS Batch was the hardest for me - I found the most helpful explanation here and summarized it below.
According to Amazon,
Amazon Elastic Container Service (Amazon ECS) is a highly scalable, high-performance container orchestration service that supports Docker containers and allows you to easily run and scale containerized applications on AWS.
With ECS you can run Docker containers on EC2 instances with AMIs pre-installed with Docker. ECS handles the installation of containers and the scaling, monitoring and management of the EC2 instances through an API or the AWS Management console. An ECS instance has Docker and an ECS Container Agent running on it. A Container Instance can run many Tasks. The Agent takes care of the communication between ECS and the instance, providing the status of running containers and managing running new ones.
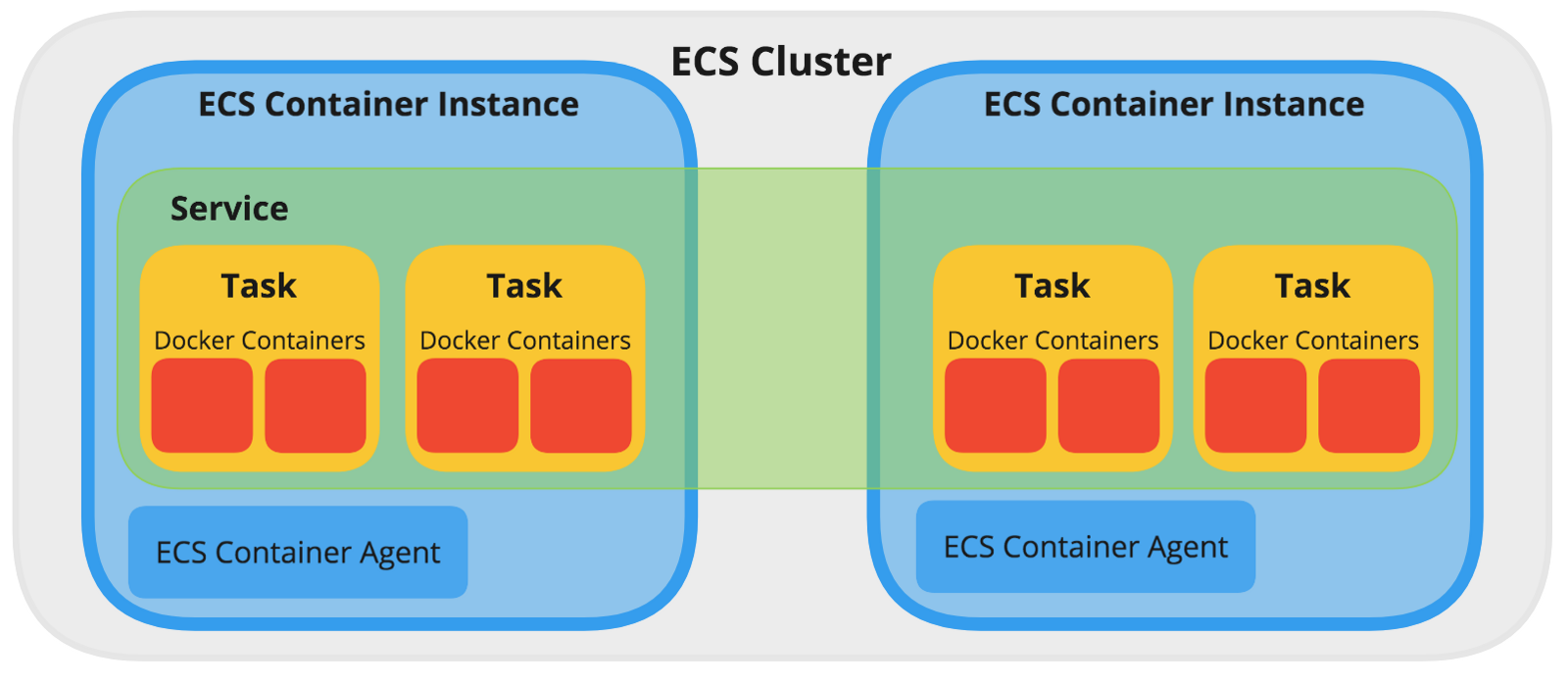
Several ECS container instances can be combined into an ECS cluster: Amazon ECS handles the logic of scheduling, maintaining, and handling scaling requests to these instances. It also takes away the work of finding the optimal placement of each Task based on your CPU and memory needs.
AWS Batch
The separation of AWS Batch from ECS was most blurry to me. Essentially, AWS Batch is build on top of regular ECS and comes with additional features such as:
- Managed compute environment: AWS handles cluster scaling in response to workload.
- Heterogenous instance types: useful when having outlier jobs taking up large amounts of resources
- Spot instances: Save money compared to on-demand instances
- Easy integration with
Cloudwatchlogs (stdoutandstderrcaptured automatically). This can also lead to insane cost, so watch out. More on that later.
AWS Batch will effectively take care of firing up instances to handle your workload and then let ECS handle the Docker orchestration and job execution.
Putting it all together
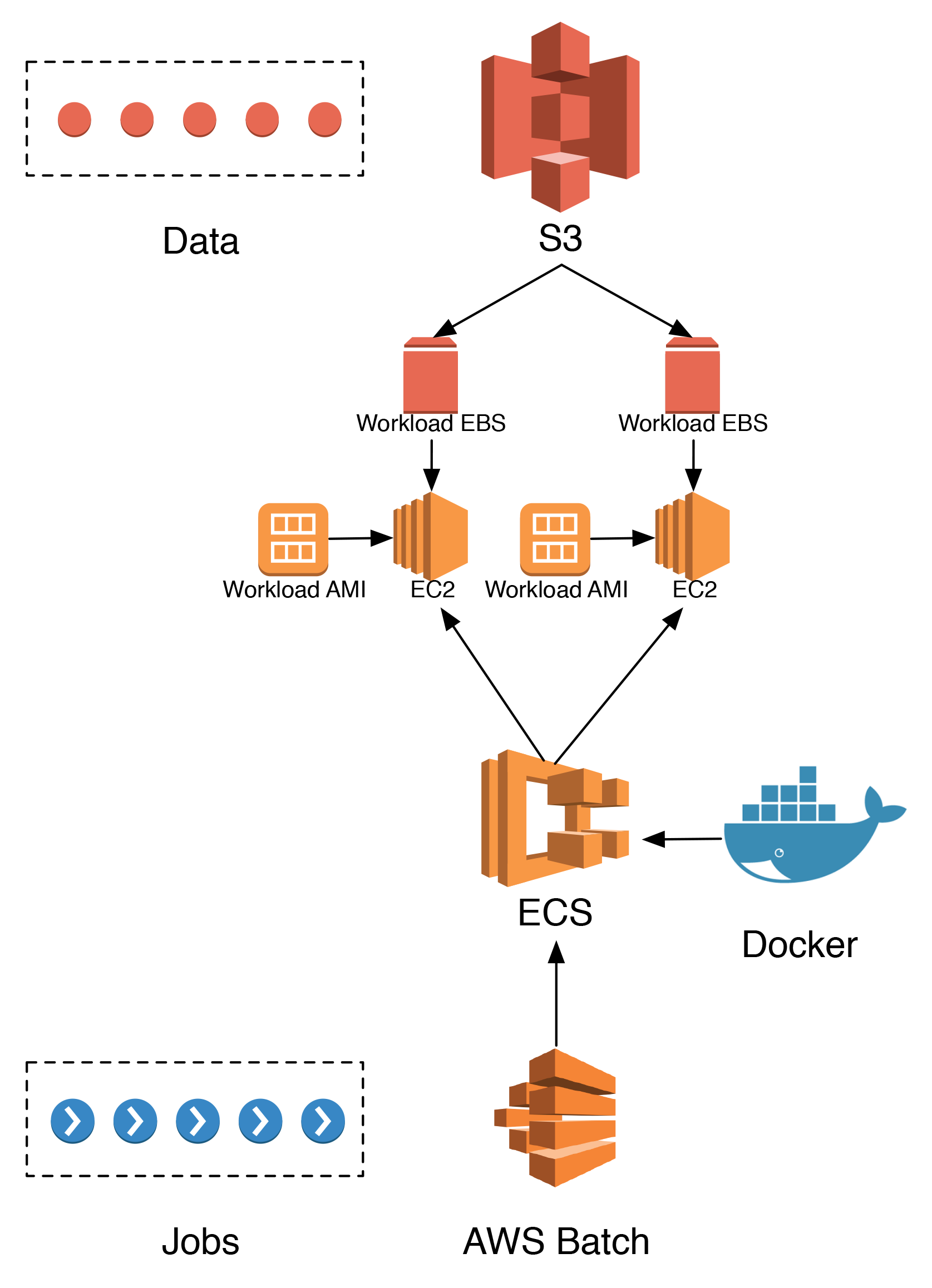
So how do all the AWS building blocks we just discussed fit together to process jobs? Let’s walk through it and conclude this post:
- All jobs we want to be processed are sent to
AWS Batch, which will assess the resources needed and fire upECSinstances accordingly. ECSwill take care of pulling the Docker images needed from a container registry (usually Docker hub) and fire up containers on theEC2instances using the pre-installed Docker daemon.- These
EC2instances have been initialized with customAMIson startup, having allECSprerequisites and additional customized resources such as e.g. theAWS CLIand additionalEBSvolume space. - All data required for this job is fetched from their long-term storage in
S3to the localEBSstorage of the respectiveEC2instance.
Now the job has everything it needs to run and will be processed. After reading this post, you should have a basic understanding what AWS building blocks an AWS batch scheduling system comprises. The next step is to then actually build the architecture for such a pipeline for which I will dedicate another comprehensive post.